You can read about data abstraction in my previous post ,in this blog I’ll talk about the abstraction barriers.When we represent a rational numbers in terms of pair with operations like make-rat and selectors like numer and denom .Basic idea behind data abstraction is to identify for each type of data object a basic set of operations in terms of which all manipulations of data object can be expressed and then using those procedures to manipulate the data.
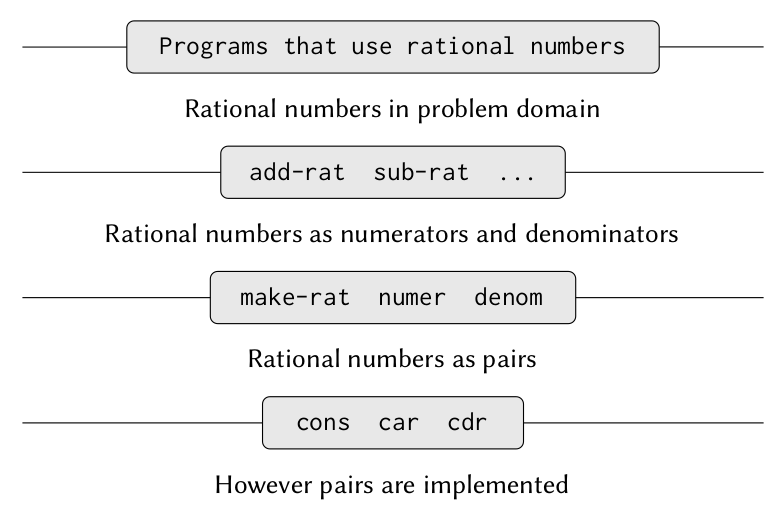
In above figure as you can see that we have levels of abstraction which fulfills different needs. But these levels are divided by horizontal boundaries which are known as Abstraction barriers. Different levels are isolated from each other. At each level , the barrier seperates the programs(above) that use the data abstraction from the program below, that implement data abstraction. As we can see from figure that we started from root level i.e primitive level and regularly abstracting different levels which doesn’t care about how below level is implemented. Programs at the top level only uses public procedure like add-rat , sub-rat ,mul-rat etc. These procedures are implemented in terms of make-rat ,numer,denom etc which are again implemented in terms of pairs.We can say that procedures at each level are interfaces that define abstraction barriers and connect the different levels.
So creating abstraction barriers is a simple idea, but the biggest advantage of it – makes program much easier to maintain and modify.But one disadvantage is the representation of data/procedures influences the program that operate on it, therefore slight change in representation can modify corresponding procedure accordingly. So this change could be expensive and time consuming if there is large program and this will depend on what level change is happening like if the change is at ground level it will be more expensive and time consuming compare to change at higher level. So we have to confine design to fewer program modules and try to make it less dependent on representation.
So abstraction barrier is one of the steps to do data abstraction in your program.
